黄仁勋2026首度来华,又要来深圳了!释放一个万亿美元级的大信号!
“
据媒体报道,2026年黄仁勋首度来华, 首站到访了英伟达在上海的新办公室,与员工交流,回顾公司2025年主要事件。
这也是黄仁勋2026年首次来华。据了解,黄仁勋此次来华期间将参加公司年会。除了上海,后续他还将前往北京及深圳。
根据知情人士,黄仁勋和员工的诸多问题中,主要聚焦在2026年重点芯片相关的话题。
根据英伟达真实路线图,继Blackwell之后,2026年的重点大概率是Rubin架构。
而就在中国行前夕,黄仁勋在达沃斯世界经济论坛上的一番发言,正在全球科技界引发震动,让全场脊背发凉:我们正在犯一个历史性错误——
把AI当作技术,而不是电和路。
这句话背后,是一场数万亿美元的财富转移:这不仅是科技革命,这是人类工作价值的重新定价。
黄仁勋表示,尽管各大企业已为这项技术投入数千亿美元,但未来仍需持续投入巨额资金。「我们需要建设价值万亿美元级的基础设施。」
黄仁勋在在2026年达沃斯论坛面对全球媒体,回应了持续数月的“美国AI泡沫”质疑称:“这并非泡沫,而是人类历史上规模最大的基础设施建设,还需要数万亿美元投资。”黄仁勋提出的“五层蛋糕”模型,将AI产业架构划分为五个层级:能源层、芯片与计算基础设施层、云基础设施层、AI模型层和应用层,强调这是支撑全球AI发展的核心基础设施框架。
”
英伟达CEO黄仁勋现身上海菜市场边吃边逛,
网友:食物不离手!
他还将前往北京及深圳,本次行程以“逛吃”为主
1月24日,《每日经济新闻》记者从知情人士处了解到,英伟达CEO黄仁勋近日来华,首站到访英伟达位于上海的新办公室。24日下午,有网友爆料称,在上海菜市场遇到正在逛街的黄仁勋。
网友拍摄的视频显示,黄仁勋现身上海陆家嘴街道乳山路锦德菜市场边吃边逛,网友称“食物不离手”。


图片来源:视频截图

图片来源:网络
水果店老板还表示,黄仁勋送了一个签名红包给他。

这也是黄仁勋2026年首次来华。据了解,黄仁勋此次来华期间将参加公司年会。除了上海,后续他还将前往北京及深圳。本次行程中,黄仁勋以“逛吃”为主,不会安排媒体采访。
另据参考消息网援引新加坡《联合早报》报道,消息人士称,黄仁勋此次赴华行程与2025年初基本一致,主要参加上海、北京和深圳分公司的新年晚会以及供应商答谢会。
据报道,中国大陆作为英伟达最重要的市场之一,黄仁勋每年春节都会例行拜访。
据央视新闻报道,当地时间1月13日,美国政府批准英伟达向中国出口其人工智能芯片H200。该决定预计将重启H200芯片对中国客户的出货。
此前,美国总统特朗普通过社交媒体表示,美国政府将允许英伟达向中国出售H200人工智能芯片。据悉,上述对华销售将由美国商务部负责审批和安全审查,美方还将从相关交易中收取约25%的费用。
1月15日,外交部发言人毛宁主持例行记者会。针对美国政府称将会允许向中国出口英伟达H200芯片,但将会对此出售进行约25%的关税征收,毛宁表示,对于美国输华芯片问题以及关税问题,中方都已经多次表明了立场。
(内容来源:每日经济新闻、每经APP、参考消息、央视新闻)
突发!黄仁勋2026首度来华!释放了一个我们正在犯的历史性错误的信号

来源:新智元
【导读】AI不是泡沫,而是人类史上最大基建狂潮!黄仁勋直言:已投数千亿,仅是开端,未来需数万亿美元打造「五层蛋糕」,从电厂到应用层全产业链爆发,就业机会前所未有。
突发!
腾讯科技独家新闻报道,2026年黄仁勋首度来华, 首站到访了英伟达在上海的新办公室,与员工交流,回顾公司2025年主要事件。
据报道,这次来华行程与2025年初基本一致,主要参加上海、北京和深圳分公司的新年晚会以及供应商答谢会。

腾讯科技:独家丨黄仁勋2026年首度来华,未提及H200
根据知情人士,黄仁勋和员工的诸多问题中,主要聚焦在2026年重点芯片相关的话题。
根据英伟达真实路线图,继Blackwell之后,2026年的重点大概率是Rubin架构。
而就在中国行前夕,黄仁勋在达沃斯世界经济论坛上的一番发言,正在全球科技界引发震动,让全场脊背发凉:我们正在犯一个历史性错误——
把AI当作技术,而不是电和路。
这句话背后,是一场数万亿美元的财富转移:
水管工、电工、建筑工人的收入未来或突破「六位数」,
而坐在办公室里的白领,可能面临第一波AI冲击。
这不仅是科技革命,这是人类工作价值的重新定价。
人工智能(AI)爆发,已拉开「史上最大规模基础设施建设」的序幕。
规模到底有多大?
黄仁勋表示,尽管各大企业已为这项技术投入数千亿美元,但未来仍需持续投入巨额资金。「我们需要建设价值万亿美元级的基础设施。」

他认为,ASI基建新工种将涌现,预测未来美国的建筑工有机会实现「六位数」收入。
人类历史上最大规模基础设施建设
2026年1月21日,瑞士达沃斯,世界经济论坛(WEF)。
在一场挤得水泄不通的主论坛上,黄仁勋(下图右)与Larry Fink(下图左)展开了一场关于AI未来的深度对话,豪言AI是「人类历史上最大规模基础设施建设」的基石。

众所周知,黄仁勋是NVIDIA创始人兼CEO,是AI时代「算力之王」;而后者Larry Fink,也不简单,是华尔街的两枚定海神针之一贝莱德(BlackRock)共同创办人、董事长、CEO。
黄仁勋提到,2025年是有记录以来风险投资规模最大的年份之一,大部分资金流向他所称的「原生AI公司」。
这些企业遍布医疗、机器人、制造与金融服务领域。黄仁勋指出:「这是首次出现足够成熟的模型,能够支撑这些行业的深度开发。」
相关投资正直接转化为就业岗位。
他特别列举了当前紧缺的技术工种:水管工、电工、建筑工人、钢铁工人、网络技术员,以及负责安装运营高端设备的专业团队。
从熟练技工到初创企业,AI正开启下一次平台级变革。
对全球打工人来说,这场变革将推动工作重心从执行任务转向实现价值。
AI 之下,工作要有目的
面对大家对AI取代人类的担忧,黄仁勋给出了反直觉的有力反击:AI不会摧毁工作,它正在让工作从「完成任务」转向「实现人生价值」 。
他以放射科医生为例。
2016年,「AI教父」辛顿曾表示:「我们现在就应该停止培训放射科医生了」,因为AI很快就能比他们做得更好。

他说得没错:近十年来,模型在各项基准测试中的表现已超越放射科医生。
然而,放射科医生的岗位数量正处于历史最高水平,平均薪资高达52万美元。
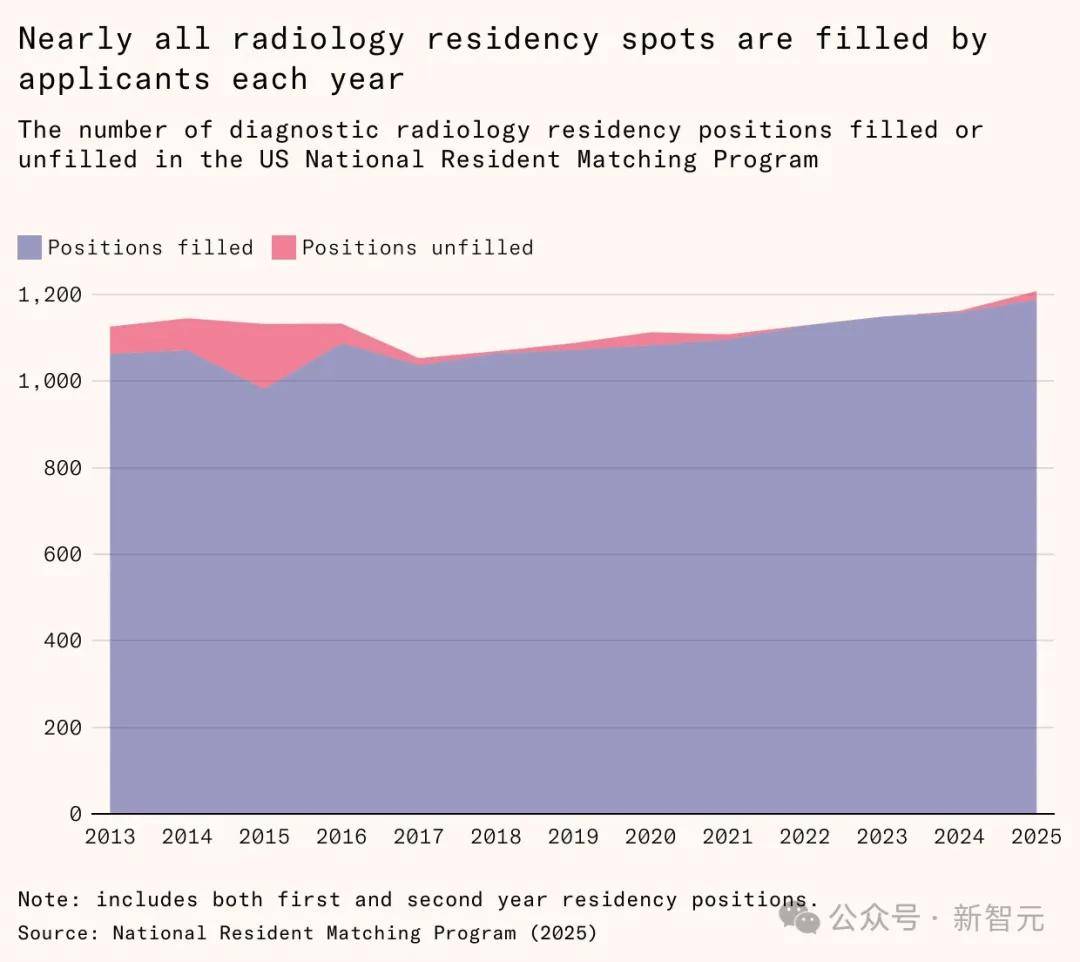
为什么?
因为医生的使命是诊断疾病和救治病人,看片子只是任务之一 。
AI处理了看片子的任务,让医生能花更多时间与病人互动,从而能接诊更多病人,从而医院效益好了,自然需要更多放射科医生。
同样的逻辑也适用于护士。
美国正面临500万护士的短缺,部分原因是护士们近一半的时间都花在填表和记录上 。
AI接管了图表记录和转录工作后,护士的工作效率提高了,医院效益变好了,反而需要招募更多护士。
作为CEO,黄仁勋幽默比喻:「若有人观察我和Fink的工作,大概会觉得我俩是打字员。」
但自动化打字不会取代他们的CEO工作,因为打字并非核心价值。
再比如,黄仁勋盛赞Claude「不可思议」,宣称「所有软件公司都需要使用它」。
黄仁勋并非突然认同Anthropic的AI安全理念,而是折服于他们的工程能力。Claude Code正在以惊人速度吞噬企业软件开发市场,以至于英伟达这家硬件公司竟公开点名推荐特定模型。
这说明AI已跨越「新奇事物」的门槛,蜕变为软件行业基础设施。
AI通过协助事务性工作,让人更能聚焦核心使命,提升效能,从而创造更大价值。
「所以关键在于:你工作的本质价值是什么?」黄仁勋最后发问。

英伟达创始人兼首席执行官黄仁勋与贝莱德董事长兼首席执行官Larry Fink在2026年瑞士达沃斯世界经济论坛年会对话
在对话中,他也淡化了外界对巨额支出承诺可能导致AI泡沫的担忧。
五层蛋糕论
AI没有泡沫
据估计,仅2025年一年,全行业就将在AI研发上投入约1.5万亿美元——
这个数字超过了几乎所有其他领域任何企业集团的名义支出。
然而,黄仁勋坚持认为,这并不是过度投资。他说,这代表着人类历史上规模最大的基础设施建设,而这还只是刚刚开始。
他进一步解释称,在芯片领域,「台积电已宣布计划新建20座芯片工厂;富士康正与我们合作,还有纬创和广达,将新建30座计算机工厂,这些工厂后续将转化为AI工厂(数据中心)。」
「美光已开始在美国投资2000亿美元,SK海力士表现非常出色,三星也做得非常出色。你们可以看到,整个芯片行业正以惊人的速度增长,」黄仁勋补充说。
而且不止单一的芯片突破。
黄仁勋将AI产业精辟地拆解为五个核心层级,重申了他的「AI五层蛋糕论」:
能源(Energy):为AI提供动力的电力基础。
芯片与计算基础设施(Chips and Computing Infrastructure):硬件算力的基石。
云数据中心(Cloud Data Centers):承载计算的枢纽。
AI模型(AI Models):智能的大脑。
应用层(ApplicationLayer):最终创造经济效益的顶端。
他特别指出,最大的经济效益将来自应用层——
AI正在重塑医疗、制造、金融服务等行业,并改变整体经济中的工作性质。

从能源发电、芯片制造到数据中心建设与云端运维,黄仁勋表示AI建设已催生大量技术工种需求。
更关键的是,他用「价格」来反证泡沫论:
如果这是泡沫,算力应该不缺、租GPU应该越来越便宜;但现实相反——GPU 很难租到,算力现货租赁价格在上涨,不只是最新一代,连两代以前的GPU也在涨。
这意味着需求来自真实业务,而不只是投机资本烧钱。
黄仁勋还举了企业调整研发预算的例子:比如制药公司把一部分投入从湿实验室转向AI超算。
AI是电,是路,是生产力
黄仁勋将AI定位为国家关键基础设施。
「AI即基础设施,」他强调,各国应像对待电力或公路那样重视AI,「必须将AI纳入国家基础设施体系」。
他呼吁各国基于本土语言文化构建自主AI能力:「开发属于自己的AI,持续优化迭代,让国家智慧融入生态系统。」
Fink质疑是否只有高学历人群才能使用或受益于AI。
黄仁勋驳斥了这一观点。
「AI超级易用——这是历史上最简单的软件,」他表示,AI工具仅用两三年已触达近十亿用户。
因此,掌握AI素养正成为必备技能:「学习如何使用AI、引导它、管理它、设立防护栏、评估结果,这些能力与领导力和团队管理同等重要。」
回到「放射科医生」,RSNA(北美放射学会)主席、 斯坦福大学医学教授Curt Langlotz之前表达过类似的观点:
AI不会取代放射科医生,但会使用AI的放射科医生将取代不会使用 AI 的放射科医生。

欧洲的AI超车机会:物理AI
对于发展中国家,黄仁勋认为AI带来了缩小长期技术差距的契机:「AI很可能弥合技术鸿沟,普惠性与资源丰沛性将发挥关键作用。」
谈到欧洲时,他特别指出制造业与工业实力是巨大优势:AI不是写出来的,是教出来的。
「机器人是世代难逢的机遇,」黄仁勋强调,这对工业基础雄厚的国家尤为关键。
「如今我们可以将工业能力、制造能力与人工智能相融合,由此迈入实体AI即机器人技术的世界,」他补充说,这为欧洲带来了「跨越」由美国主导的软件时代的机遇。
「我认为,为了在欧洲构建繁荣的AI生态系统,我们必须认真对待能源供给的增长,加大对基础设施层的投资,这一点是确定无疑的,」 黄仁勋说道
Fink总结讨论时表示,这场对话说明世界远未形成AI泡沫,真正的问题在于:「我们的投资够吗?」
黄仁勋赞同这一判断,指出庞大投资势在必行:我们必须为AI技术栈的所有上层建筑构建必要基础设施。
他形容这一机遇「非同寻常,每个人都应参与其中」。
他重申2025年全球风投规模创历史新高,超千亿美元资金流向全球,其中大部分注入AI原生初创企业。「这些公司正在构建上层的应用生态,」黄仁勋说,「而它们需要基础设施与投资来筑造未来。」
Fink补充道,确保增长红利被广泛共享至关重要:
我相信全球养老基金参与这场变革将是绝佳投资机遇,能与AI世界共同成长。
我们必须让普通养老金领取者和储蓄者分享这份增长。若只能作壁上观,他们将被时代抛在后面。
参考资料:
https://www.wsj.com/tech/ai/nvidia-ceo-says-ai-needs-more-investment-in-defiance-of-bubble-fears-9dabba63
https://blogs.nvidia.com/blog/davos-wef-blackrock-ceo-larry-fink-jensen-huang/
https://qz.com/jensen-huang-nvidia-speech-davos-2026
https://finance.yahoo.com/news/nvidia-ceo-jensen-huang-trillions-of-dollars-of-ai-infrastructure-needs-to-be-built-144212721.html
https://news.qq.com/rain/a/20260123A07C5A00
老黄万亿美元梦成真,英伟达版「世界模型」震撼问世

来源:新智元
【导读】黄仁勋的预言成真!从Sora的梦幻视频到英伟达的3D通才模型,AI不再只是「看和说」,而是真正「动手」构建3D世界,开启机器人时代的无限可能。
黄仁勋没有吹牛!
AI不能只会看、会说、会生成,它还必须理解并遵守物理世界的规则。
现在,英伟达补上了关键拼图——
让AI从「生成画面」升级为「生成可行动的3D世界」,不仅能描述世界,还能一步步搭建世界、修改世界、纠错迭代。
时间拨回到两年前, 2024年2月。
OpenAI发布了一段「东京街头漫步」的Sora视频,震惊世界,硅谷集体狂欢。

人们高呼「现实不存在了」,仿佛人终于可以「言出法随」、重造万物。
但在一片喧嚣中,那个穿皮衣的男人始终保持冷静,甚至带有一丝不屑。
在2024年和2025年的多次演讲中,黄仁勋像复读机一样不断重复——「Physical AI」(物理AI)。
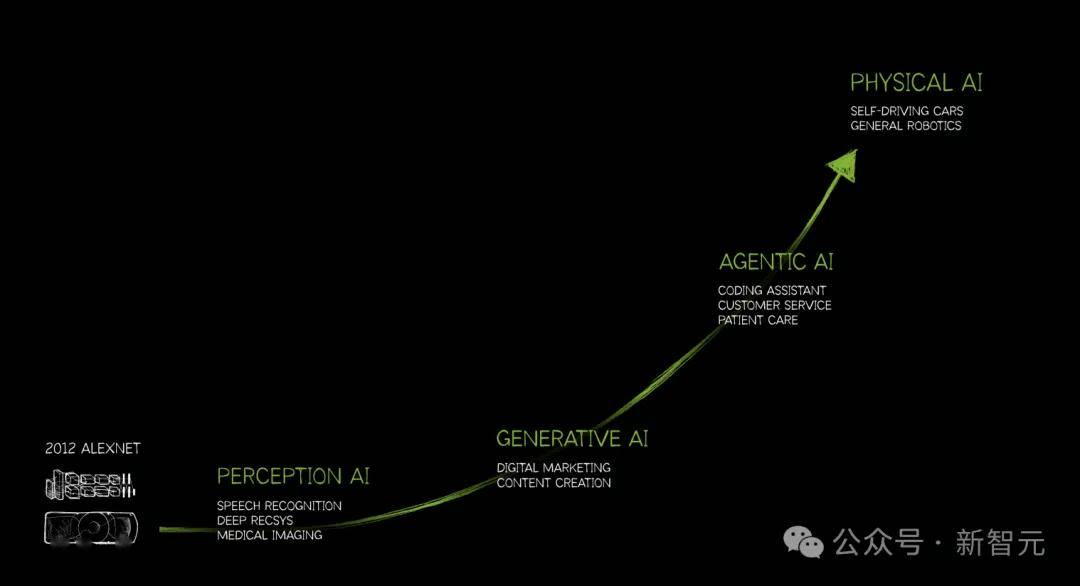
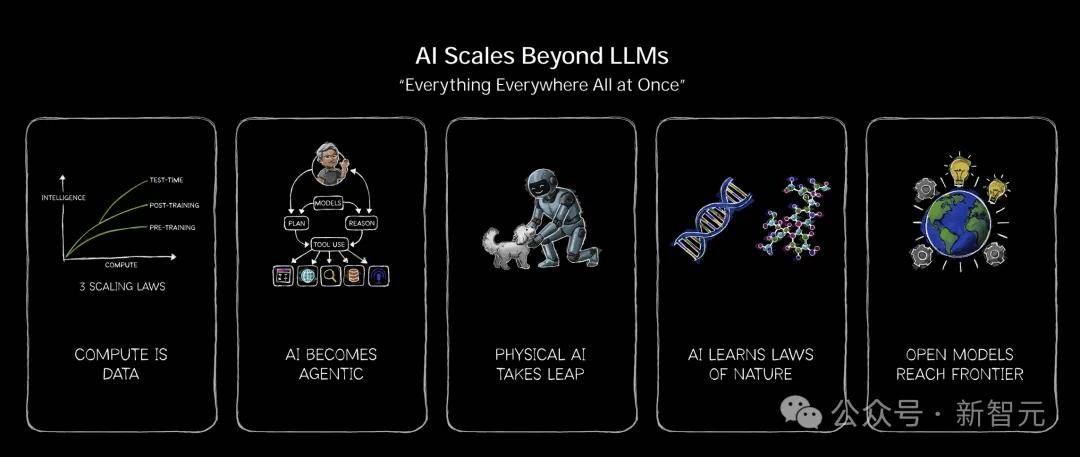
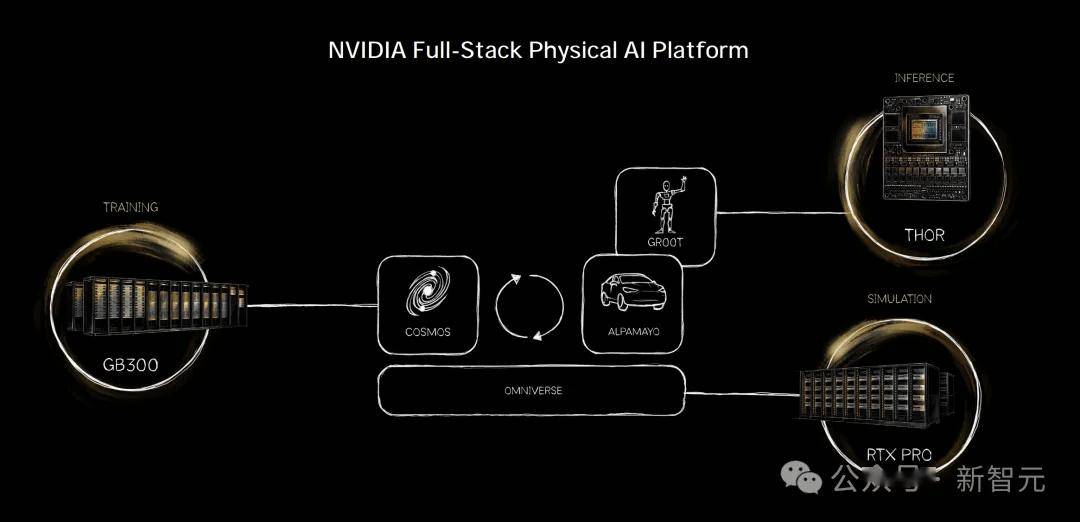
上下
反驳视频生成模型的理由是这样的:
AI生成的视频很美,但如果你走进那个视频,试图拿起桌上的杯子,你的手会穿过去。
杯子没有重量,没有摩擦力,没有物理法则。
那不是世界,那是动画片。下一波浪潮,必须是懂物理的AI。
当时,很多人以为这只是老黄的营销话术,最终目的是为了推销昂贵的Omniverse平台和RTX显卡。
直到CES 2026,大家才明白老黄说的对。
刚刚,我们发现英伟达甩出了一篇新年第一篇论文:3D通才模型。
链接:https://research.nvidia.com/publication/2026-03_3d-generalist-vision-language-action-models-crafting-3d-worlds
如果说ChatGPT是AI学会了「说话」,Sora是AI学会了「做梦」,那么英伟达的这个新模型,就是让AI真正「睁眼看世界,动手造世界」。
这是图形学的胜利,这是「硅基生命」长出四肢的前夜。
老黄没有画饼——
物理AI的「ChatGPT时刻」,在这一刻,正式降临。
英伟达开年首篇论文
手搓赛博房之家
这篇论文由英伟达和斯坦福大学合作,正式发表在今年第十三届国际三维视觉会议上,标题相当拗口——
《3D Generalist:Vision-Language-Action Models for Crafting 3D Worlds》(3D通才:用于构建三维世界的视觉-语言-动作模型)。
2026年3月20日至23日,第十三届国际三维视觉会议2在加拿大不列颠哥伦比亚省温哥华的温哥华会议中心以线下形式举行
我们要读懂这次技术革命,首先要从这篇论文标题里,把那个最核心的单词揪出来。
请盯住这个词:Action(动作/行动)。
这是整个逻辑的起点。
在过去的三年里,无论是Midjourney画图,还是Runway生成视频,AI扮演的角色都是「观察者」和「梦想家」。
它看了一亿张猫的照片,然后根据概率,在屏幕上预测下一排像素应该是什么颜色,从而凑出一只猫的样子。
它不知道猫有骨骼,不知道猫毛有触感,它只是在「模仿视觉信号」。
但英伟达的VLA(Vision-Language-Action)模型,彻底颠覆了这个逻辑。
它不再是画家,而是「全能手」。
你只要输入一句话,3D-GENERALIST就能输出包含完整3D布局的房屋。
这些3D布局包括材料、固定装置(比如门和窗户)、3D资产以及照明配置。

背后的理念是,构建一个既详细又与文本描述相符的3D环境,应该被视为一个过程,需要依次做出决策。
因此,通过场景级和素材级的策略,他们不断改进和优化这些3D环境。
在提出的框架中,第一个重要的模块是全景环境生成。
如图2所示,这个模块能够根据文本描述初始化一个基础的3D房间模型,包括墙壁、地板以及固定装置,如门和窗户。
为了避免传统方法过于简化或不切实际的问题,他们首先利用全景扩散模型生成一个360°的图像作为指导,然后通过逆图形技术构建3D环境。
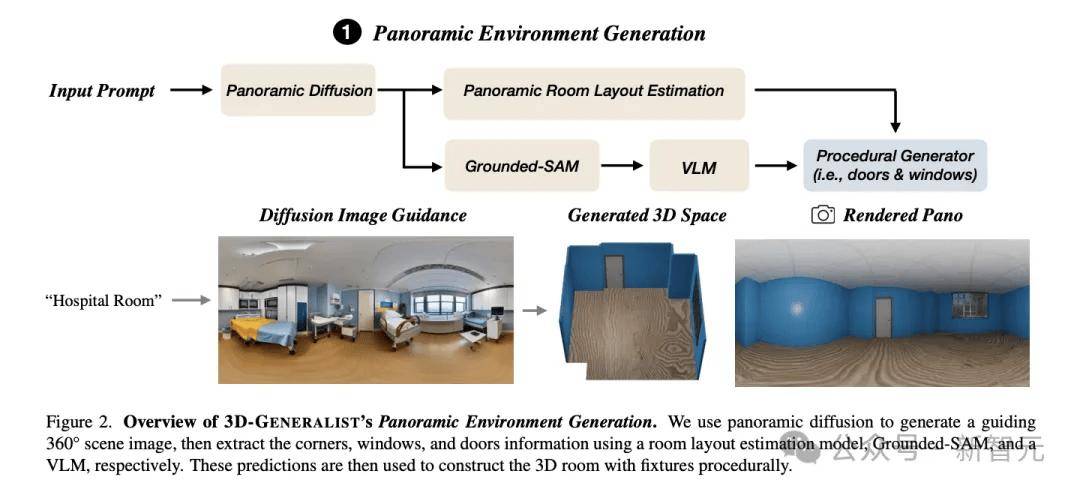
图2:3D-GENERALIST全景环境生成概述。全景扩散模型生成引导性360°场景图像,然后房间布局估计模型、Grounded-SAM和视觉语言模型提取角落、窗户和门的信息。这些预测随后被用于通过程序化方式构建带有构件的3D房间
这个过程包括以下几个步骤:
房间布局估算:利用全景图像和HorizonNet模型,推断出房间的基本结构,如墙壁、地板和天花板。
固定装置分割:使用Grounded SAM技术对窗户和门进行分割。
视觉-语言模型注释:通过GPT-4o这样的视觉-语言模型,分析每个分割区域,确定其类型(例如单扇门、双扇门、滑动门或折叠门)和材料(如门框、门体和门把手的材料)。
过程化生成:最后,根据3D位置的相应信息,房间、门和窗户被逐步构建出来。
3D-Generalist 使用扩散模型生成全景图像,并通过逆向图形(inverse graphics)流水线来创建3D环境的结构。
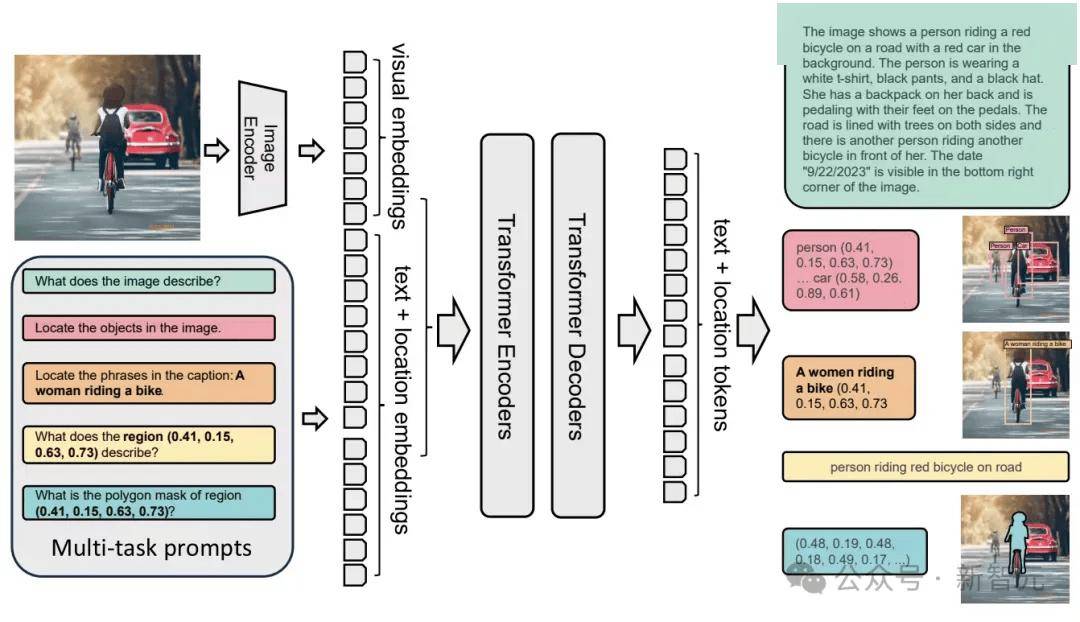
3D-Generalist采用视觉-语言-动作(VLA)模型来生成代码,用于构建与修改最终3D环境的各个方面(材质、光照、素材与布局)。
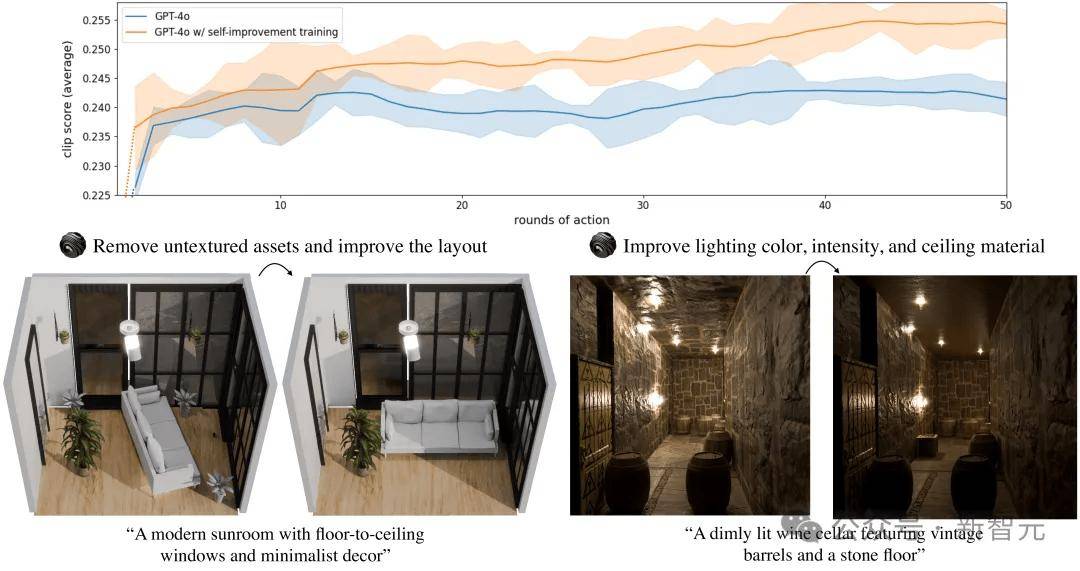
该VLA通过一个自我改进训练循环进行微调,以优化与提示词(prompt)的对齐效果。
3D-Generalist还使用了另一个VLA来处理多样化的小物体摆放任务,即使 3D素材是无标注(unlabeled)的也能完成。
微调后(After Finetuning),3D-Generalist涌现出自我纠错行为。
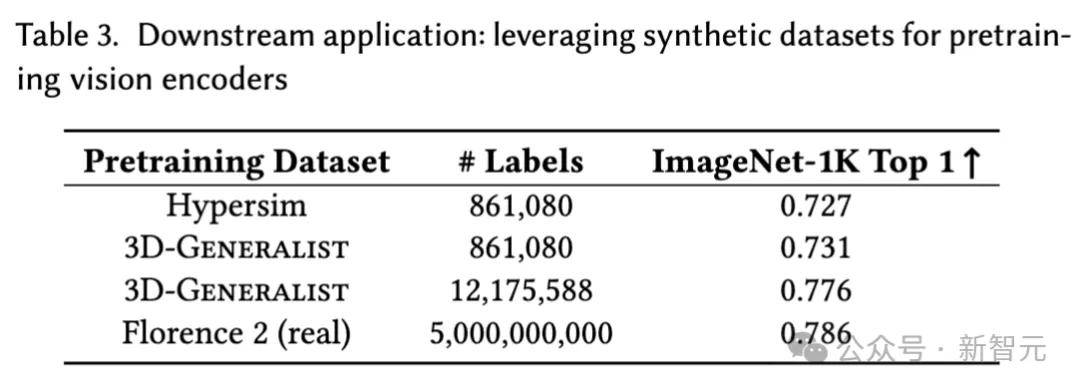
研究团队还使用Florence-2框架,在由3D-Generalist生成的3D环境渲染得到的合成数据上训练一个视觉基础模型。
结果表明:其效果接近使用规模大几个数量级的真实数据所能达到的效果。
物理AI的ChatGPT时刻,已开启?
如果你认为黄仁勋费尽心机搞这个,只是为了让你玩游戏更爽,或者让视觉特效更便宜,那你严重低估了英伟达的野心。
英伟达不只是买买游戏显卡,更致力于解决「智能」算力问题。
这篇论文的真正战略意图,其实藏在英伟达宏大的「具身智能」(Embodied AI)版图中。
老黄早已押注机器人,他认为那是一个数万亿美元的机遇:

这次无疑是英伟达「秀肌肉」。
请看这个逻辑链条:
我们想要全能的机器人(比如特斯拉Optimus,或英伟达Project GR00T)。
机器人需要学会像人一样处理复杂的物理世界(怎么拿鸡蛋不碎?怎么在湿滑地板上走路?)。
在真实世界里训练机器人太慢、太贵、且不可逆(你不能让机器人摔坏一万个鸡蛋,或者摔断一千次腿)。
解决方案:把机器人扔进「虚拟世界」里训练。
但是,以前的虚拟世界(模拟器)不仅搭建很慢,而且不够真实。
如果模拟器里的物理规则和现实不一样,机器人学出来的本事就是花拳绣腿,一上真机就扑街。
现在,新模型「3D通才」补上了这一环。
有了这个技术,英伟达可以瞬间生成数百万个包含不同物理变量的「虚拟平行宇宙」。
场景A:地板刚拖过,很滑,光线昏暗。
场景B:地板铺了地毯,摩擦力大,强光照射。
场景C:地板上散落着乐高积木,障碍物复杂。
在这个无限生成的「3D物理世界」里,机器人大脑可以在一天之内经历人类几百年的训练时长。它在虚拟世界里摔倒一亿次,就是为了在现实世界里稳稳地迈出第一步。
在英伟达的Omniverse生态中,研究团队使用Omniverse Replicator实现大规模合成数据生成,并支持域随机化(domain randomization);而Isaac Lab提供可直接使用的具身载体(例如人形机器人),可在这些生成环境中进行机器人仿真。


这才是「物理AI」的终极目标:打通Sim-to-Real(从模拟到现实)的最后一公里。
黄仁勋构建的不仅仅是一个生成的引擎,它是硅基生命诞生的子宫。
所有移动之物,终将自主
当AI不仅掌握了人类的语言(GPT),掌握了人类的视觉(Sora),现在又掌握了构建物理世界的法则(Physcial AI)时,虚拟与现实的界限,将不再是泾渭分明的。
我们在屏幕里创造的世界,将拥有和现实世界一样的重力、光影和因果律。
而我们在现实世界里的机器人,将拥有在数亿个虚拟世界里磨练出来的智慧。
在2024年的SIGGRAPH大会上,黄仁勋曾说:「Everything that moves will be autonomous.」(所有移动之物,终将自主。)

当时我们以为他在说机器人。
现在看来,他说的是整个物理世界。
作者介绍
Fan-Yun Sun

Fan-Yun Sun是斯坦福大学AI实验室(SAIL)的计算机科学博士生,隶属于Autonomous Agents Lab和斯坦福视觉与学习实验室(SVL)。
在读博期间,他也深度参与了英伟达研究院的工作,曾效力于学习与感知研究组、Metropolis深度学习(Omniverse)以及自动驾驶汽车研究组。
他的研究兴趣主要在于生成具身(3D)环境与数据,用于训练机器人和强化学习策略;致力于推动具身、多模态基础模型及其推理能力的发展。
Shengguang Wu

Shengguang Wu目前是斯坦福大学计算机科学系的博士生,师从Serena Yeung-Levy教授。
他在北京大学获得硕士学位,导师为Qi Su教授;此前,他也曾在Qwen团队担任研究实习生。
他的研究致力于赋予机器跨多模态的类人学习与推理能力,并推动现实应用的落地。
多模态Grounding与推理:利用视觉洞察来优化基于语言的推理,同时引入文本反馈来指导细粒度的视觉感知。
自我提升:让AI智能体能够从交互中学习并持续自我进化——主动适应新信息,并随着新任务的出现不断成长。
Jiajun Wu

吴佳俊是斯坦福大学计算机科学系助理教授,同时兼任心理学系助理教授。
在加入斯坦福之前,他曾在Google Research担任访问研究员,与Noah Snavely合作。
他本科毕业于清华大学交叉信息研究院「姚班」,师从屠卓文(Zhuowen Tu)教授。在清华期间,他曾连续三年保持年级第一,并荣获清华大学最高荣誉——特等奖学金以及「中国大学生年度人物」称号。
随后,他在麻省理工学院获得电气工程与计算机科学博士学位,导师是Bill Freeman和Josh Tenenbaum。
吴佳俊的团队致力于物理场景理解的研究——即构建能够「看」见世界、进行推理并与物理世界互动的机器,其代表性项目包括Galileo、MarrNet、4D Roses、Neuro-Symbolic Concept Learner以及Scene Language。
除了开发表征本身,团队还同步探索这些表征在各个领域的应用:
多模态感知,代表项目如ObjectFolder和RealImpact;
4D物理世界的视觉生成,代表项目如3D-GAN、pi-GAN、Point-Voxel Diffusion、SDEdit和WonderWorld;
基于物理概念接地的视觉推理,代表项目如NS-VQA、Shape Programs、CLEVRER和LEFT;
机器人学与具身智能,代表项目如RoboCook和BEHAVIOR。
Shangru Li

Shangru Li是英伟达高级系统软件工程师,长期从事智能视频分析(IVA)和Metropolis平台的相关工作。
他拥有宾夕法尼亚大学计算机图形学与游戏技术工程硕士学位,以及广东外语外贸大学计算机软件工程学士学位。
其他华人作者还有:
Haoming Zou (Stanford University)
Yu-Hsin Chou (Stanford University)
Xunlei Wu (NVIDIA)
参考资料:
https://research.nvidia.com/publication/2026-03_3d-generalist-vision-language-action-models-crafting-3d-worlds