获5亿美元融资后,杨植麟揭秘KIMI K2训练 QK-Clip驯服Muon

雷递网 乐天 1月11日
最近一段时间,大模型行业非常热闹,智谱AI和minimax相继上市,月之暗面KIMI获5亿美元融资,整个行业也从原来的概念,转向了商业化落地。

月之暗面KIMI创始人杨植麟今日在智谱发起的一场技术活动上揭秘Kimi预训练策略:1,Token efficienc,用尽可能少的Token得到一样的效果;2,实现长上下文(Long context),尽可能延长,Loss降低。
“这是我们整体的优化,Token efficienc再乘以Long Context,最终就可以做到非常好的agent智能。”
杨植麟认为,更好的预训练和基础模型是减少了搜索空间,提升了更好的先验。他指出,KIMI要在K2的基础上做更多的Scaling,这不只是加算力,很重要的点是接下来的模型有更多的Taste,更多的品位和审美。
刚宣布融资5亿美元
近期,月之暗面KIMI宣布完成5亿美元C轮融资且大幅超募,当前现金持有量超100亿。
杨植麟说,相比于二级市场,公司判断还可以从一级市场募集更大量资金,事实上,公司B/C轮融资金额就超过绝大部分IPO募资及上市公司的定向增发。所以月之暗面短期不着急上市,也不以上市为目的。
“当然未来我们计划将上市作为手段来加速AGI,择时而动,主动权掌握在我们手中。”
杨植麟还说,C轮融资资金将用于更加激进地扩增显卡,加速K3模型的训练和研发。部分资金也将用于2026年的激励计划和期权回购计划。2025年,基于sota结果产出,调薪、期权奖励、现金奖励等各种激励措施累计324人次。2026年春节之前会确定K2 Thinking及后续模型和产品发布的奖励方案并发放。2026年公司的平均激励预计是2025年的200%,同时计划大幅上调期权回购额度。
他还透露,Kimi产品从5月开始高频推出新的agent功能,发布了Researcher, OK Computer, PPT, Kimi Code等新品,功能日渐强大。借助K2模型的sota表现,C端商业化指数增长,9-11月,海外和国内付费用户数平均MoM增长超过170%。同时,K2 Thinking的发布也带动了API收入的增加,9-11月海外API收入增长4倍。
当下minimax在港股上市,受到热烈追捧,公司市值已超过千亿港元,有投资人认为,月之暗面在资本动作层面有所落后,可能会是很大的隐患。
以下是杨植麟演讲核心内容:
杨植麟:从2019年到现在所有的大模型基本上基于同一个第一性原理,Scaling Law,也是把能源转化成智能的一个视角。如果有更好的方法,或者更好的芯片,其实可以把能源更好和更多转化成更高级的智能。核心的点可以总结到这三张图里,就是有更多的算力、数据、模型参数之后,你的模型的loss可以线性下降,这是整个技术发展的基础。
这里面很重要的一个点是我们可以看最早提出来的Scaling Law的这篇文章,就是Kaplan Law的Scaling Law,里面对比了Transformer和Lstm在Scaling Law意义下的的区别,我觉得是很有意思。左边图的横坐标是你的参数量,纵坐标是Test Loss,所以Loss是越低越好。
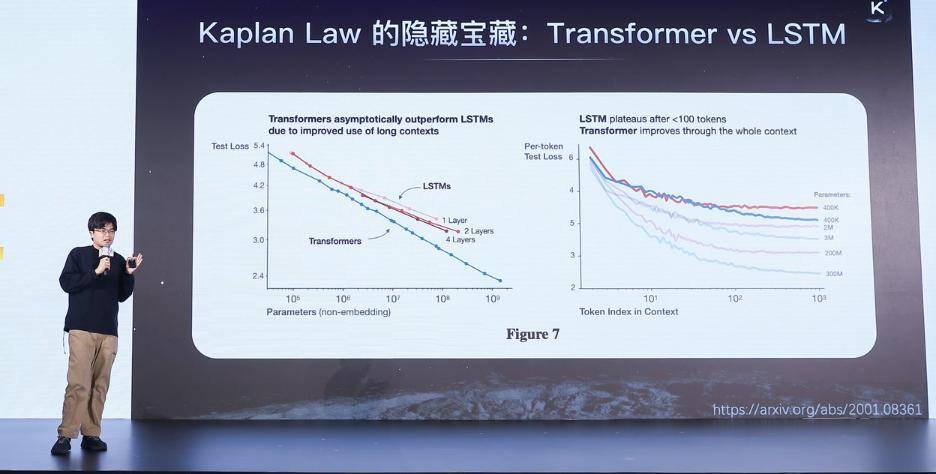
你可以看到不管是在什么样的参数量下,Transformer的Loss都会比LSTM更低,也就是在Scaling Law的尺度下,可以用更少的FLoss或者更少的参数,就能得到更好的Scaling效果。
当然,这是一个常识,后面Transformer成为主流架构的一个核心原因,是因为它是一个在Scaling Law上有更好的表现。
你可以认为今天所有的模型架构的迭代,其实都是为了寻找一条线能够更接近左下角。如果你的网络架构越接近左下角,其实你就是更好的网络架构。在当前的情况下,它会变的更有意义。
就是因为这个世界上互联网上的存量数据是有限,它是一个有限集合,高质量的数据增长速度其实是赶不上这个模型迭代的速度,所以当你有一个越靠左下角的象限的时候,你的智能上限就会更高。
但是,真正关键的是右边这张图,右边这张图非常有意思的,很多人可能会忽略,为什么Transformer会更好。它做了一个拆解,横坐标Token efficienc,什么是Token efficienc呢?比如说当你给一个一百K的上下文,你会去数里面第一、第二、第三、第四一到第一百个Token的log是什么,比如说还是loss,但是它是一个position loss,因为你的横坐标是你的Token efficienc,表示你在这个序列里面到底是第几个Token。
你可以看到在最前面的一百个Token里面,Transformer和LSTM完全一样的,基本上这两条线是交错在一起。就是说当你在很短的Context的时候,你去预测接下来的Context会变成什么样,基本上是相等的效果。
所以在一百很短的Context下面,其实Transformer并不是一个更好的架构。但是更好的架构体现在当你的Context非常长的时候,上涨到一千个,当时的规模还比较小,现在动不动就是几十万,当时还是在一千上个做实验,上涨到一千的时候,明显的看到这根蓝线就会变到红线的下面,Transformer显著的比LSTM更好。
这也是另外一个视角拆解它是一个很重要的指标。在不同的Context长度下,你的优势有多大。这个问题在Agentic时代会变的非常重要,因为很多agent的任务要求非常长的长上下文,你要问题很复杂的任务,所以当你一个架构有更低的position loss,说明它在做Agent任务的时候,会有好的多的技术上的潜力。
所以我们预训练策略或者模型设计策略,围绕刚刚两个维度做,第一个是Token efficienc,我们希望做的事情是尽可能把这条线往左边平移,当你越往左边移动的时候,你的Token efficienc就越高,意味着你可以用尽可能少的Token得到一样的效果。当你的整个预训练Token不够用的时候,Token是常量,吃完所有Token的时候你的智能上限更高,因为你的Loss更低,这是我们做预训练很重要的指标和优化方向。

第二个方向是Long contex,看一下右边的图,横坐标是你在里面是第几个Token,做作表是Test loss,你希望做的事情是让它尽可能延长,当你延长之后Loss就会降低。这也是解释了今天非常复杂的任务,必须在超长的Context下才能够完成。是因为延长了Context之后,Loss必然是下降,而且只有一个好的Agentic才能下降的更多,如果你是LSTM、CNN、RNN这种架构,到一百Token就停了,所以就简单的做翻译的任务,但是你永远做不了一个编程人物,没有办法从零到一实现一个代码库的编写。这是我们整体的优化,Token efficienc再乘以Long Context两个东西,最终就可以做到非常好的agent智能。
所以在这里面有两个主要的工作,第一个是米用MUON优化器,是工业界二阶优化器,传统的是十几年前,2014年Adam优化器提出之后,它做标志性的一阶优化器。基本上用了十年的时间,可能主流大模型都是基于Adam训练,但是我们发现可能基于MUON二阶优化器,它的效果会非常好,好的体现在它有两倍的Token efficienc的提升。
当你看这两条线的时候,只用50%的数据就可以达到一样的Test Loss,等价的话是如果用一样的数据,你的Loss小或多,就会有一倍的Scaling的效果。右边是我们最新研究的kimi Liner的架构,当你的这条线拉长的时候,降低的幅度是非常大的,也就是你在LContext等各种任务上的效果会显著的变好。最后是这两个东西乘起来,我们认为在模型的训练策略上,可以达到最好的agent的效果。
这些都是为做出来更好的agent,为什么要Token efficiency,本质上Agent的推理或者AgentRL的训练是搜索过程,比如说你想从头开发一个Lineaxr,你想从零做这个事情,本质上是搜索问题,如果你有无限的数据,可以把所有可能的情况枚举遍,看一看里面哪个东西是好的操作系统,你让AI开发出来Linearx,提升它的效率,之前的agent是你用模型做很好的先验,过程中不需要枚举每一种可能的Token组合的情况,因为很多组合是没有意义或者错的,更好的预训练和基础模型是减少了搜索空间,提升了更好的先验。
今天有很多人研究怎么去减少先验,最终有可能是在先验非常少,或者几乎没有的情况下有可能实现AGI。但是我认为基于先验实现AGI,还是会更早发生,整个领域先基于先验实现AGI,你再去探索先验非常低的情况下,越来越低的情况下实现SCI的方式。
这里等价对应的是更强的先验,你是在有限数据的情况下,同样是一样多的数据,但是脑容量更大,学习效率更高,智能更高,有更好的先验就可以得到更强的agent。context是另外一个维度,你的Agent行为,需要它的工作记忆,所以你有更强的环境感知,做更长程的任务,最后是这两个东西的结合。
我们在这个基础上,整个2025年kimi的迭代是沿着刚说的两个方向做了新的探索和实践。
首先是Muon优化器,我们曾经做了非常多的实验,发现有很多比较重要的技巧。比如说需要加入VDK,你在搜索的过程中,原来是Adam的优化器,可能是接近1.0,如果用Muon的话,对照它的尺度其实效果会更好。通过这些比较重要的改进,我们得到了一个真正意义上比较好,而且在各种方面经得起时间考验的优化器,有2倍的Token efficienc提升。
所以,大家注意的是这里的efficienc不仅仅是efficienc,其实是智能上限,因为你的Token数量有限。我们也做了很多公平的比较,基本上所有的任务都会有提升,本质上是等价相当于预训练了别人的两倍Token。

我们在提升这个优化器的过程中,能看到一些问题,在一个中等规模的实验上,发现Muon的优化过程里会出现一些挑战,左边这张图横坐标是训练的步数,纵坐标是最大的Logit取值,它是一个爆炸式的增长,其实是不健康的,反映在右边的非常高的时候,你的Logit训练就有可能不收敛,Loss会爆炸,出现一些不稳定现象,其实这个模型最后的效果也不会好。
这里面很重要的一个点是通过一个新的方法解决Muon爆炸的问题,我们也试了很多方法,QK-clip效果非常火,但是这里有一些细节,你做QK映射的话,会乘上一个数值,这个数值是由当前QK最大的Logit决定的,可以动态的让它clip特定的取值里面。
效果就是这样的,一个加Clip,一个没有。左边这两条线,但是这两条线是完全重叠在一起的,你可能看不出来,其实是完全重叠在一起。说明你加了Clip之后,对效果是没有任何影响,可以复现任何效果,但是logit会健康很多。右边开始涨了,Logits涨到一百QK就发挥作用了,发现可能我不需要这个东西,这个时候会自动降下来,所以其实是很好稳定训练的作用,使得全新的优化器可以在一万亿参数的kimiK2的级别做稳定训练,不然就像之前那样炸了。
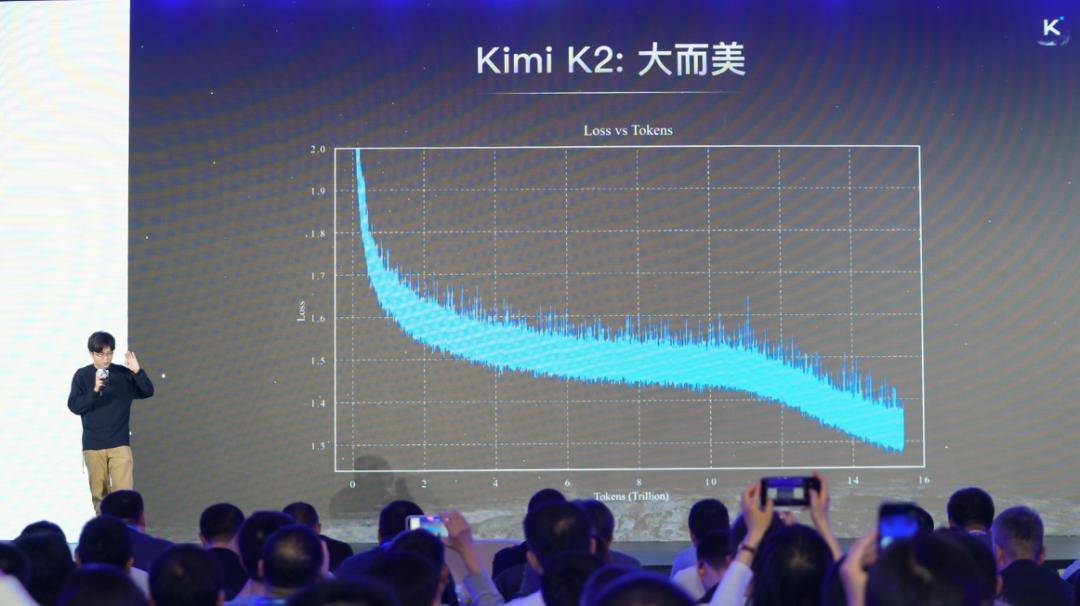
这张图是2025年见过最漂亮的东西,这个是世界上最美的东西。它是一个完全平稳下降的Loss曲线,在整个15T的Token训练中没有任何的问题,可以全部把logits压下来,平稳的收敛到一个非常好的点上。当你有一个优雅的方法,就可以得到一个优雅的结果。
在kimiK2很好的模型上面,我们又做了很多强化学习,后训练等等,但是这不是今天重点,重要的是有几个点,我们在各种agent的能力上全面提升,而且可以对标美国前沿的公司。同时,很重要的一个点是在最核心的点上,比如说HLE,里面99%的题我都不知道怎么做,但是模型现在可以做到45%的准确率,而且比OpenAI更高,你在最核心的数据上比美国公司更好,这是很重要的亮点。同时,它是一个完全agent的模型,kimiK2是中国第一个agent模型,K2 Thinking升级以后,可以完成两百百步的工具调用,解决一个很难的题的时候用它写一写程序。两三百步之后,可以完成我完全看不懂的题,但是它的答案是对的。

得益于这些发展,我觉得很多中国的开源模型逐渐成为新的标准,包括前段时间eda发布新的产品,现在也有中国很多开源模型做标准的测试,这也是开源很大的一个好处,我们希望有更多的中国的开源力量,中国的模型能够逐渐去成为标准的制定者。
在K2之后我们在持续探索下一代模型有可能长什么样,我刚刚讲到开源的kimiLinear的工作,这个工作也是我们前期的尝试,接下来还会在这个基础上做更多的优化和改进来训练K3模型。最重要的一个改进是kimi Delta Attention,它是一个新的线性注意力机制,这个技术有一段时间,但是一直没有成为主流模型,或者说最前沿的模型都还没有用上这个技术。

最主要的原因是在长距离任务上会掉点,当你的Context变长之后,你用线性注意力效果是打不过全注意力的,打不过原始的Transformer。这是很重要的问题,因为现在很多任务需要长程的能力,Context变长之后,效果变差了,可能不太能去换。
所以,这里面kimi Linear最重要的一点是让这种线性注意力的机制能够在很长程的任务上,甚至比全注意力做的更好,但是同时又更快,因为它是线性的,所以它的效率会高非常多,一百万个Context的话,可能高6到10倍的端到端的速度上的优势。同时又可以改进很多现有的线性注意力缺点,可能就是表达能力不够,导致了效果不够好,所以kimi Linear是第一个能够在线性注意力上不管是在短程任务,还是在长输入、长输出任务效果都比全注意力机制更好的一个线性注意力的架构。所以,它在实践里面会有非常重要的作用。

我们稍微看一下具体长什么样子,S表示当前线性的数据,可以看到它全部是线性的,ST相对ST减一来说的操作,称之为线性注意力。这里面很重要的一个点是中间的对角化矩阵,FT每一个维度都会乘上一个值,等于说对于这个状态里面的每一个维度都可以精准的控制到底有多少记忆是从ST减1留到ST。这个是很重要的点,它的表达能力会有很大增强,增强的同时如果你是一个非常粗糙或者没有优化过的数据,你的效率会大幅度降低,在这里面我们做了非常多的优化,你可以把刚才的那个数值做很多变化之后得到下面的形式。它在工程实现上就可以得到很多好处,你去对比DPLR,我们在数据上有优势,减少矩阵操作。
所以整体的效率是非常高的,你要得到一个好的架构,需要把很多底层的优化和模型的架构联合在一起,你不能只改动一些架构,如果没有高效的实现,很难得到一个很好的效果。但是同时相比之前的线性注意力架构又有一个显著的优势,表达能力更强。
这张图里面的效果看一下,左边是性能对比,我们会考察两种任务,一种是短程的任务,MMLU,这些都是公平的比较,用完全一样的数据,一样大小的模型去跑。在短程上会显著做的更好,在长程任务上是更好的效果,相比于之前的很多线性注意力和全注意力的架构。同时,右边的这张图的速度也是显著的变快,基本上跟之前的线性的注意力一样快,但是比全注意力要快非常多。
接下来在K2的基础上做更多的Scaling,当然这个Scaling并不只是加算力。而是说很多是技术改进,这些技术改进也会等效的变成Scaling的优势。当然这里面很重要的一个点是除了架构、优化器这样的挑战,更好的数据。很重要的点是接下来的模型有更多的Taste,更多的品位和审美。
我觉得模型是一个很不一样的东西,做模型的过程本质上是在创造一种世界观,你觉得什么样的东西是好的,一个好的AI应该是有什么样的表现,应该追求什么样的价值观,有点像乔布斯讲的(Taste)这是我们很相信的一个东西,因为智能和很多别的东西不一样,每个模型产生的Token,本身不是一个可交换的东西。如果你今天看很多事情是相同的,你在深圳产生的一度电和北京一样,银行帐户里面最后一分钱是完全一样,它是等价交换。
但是智能并不是这样,一个CEO产生的智能和一个设计师产生的智能和一个音乐家产生的智能是不同的。在智能的维度,你有非常多的Taste的空间,空间是指数增加,你会有更多新的Taste出来,不是说这个模型会趋同,这是接下来我们很重要的一个目标。
我也经常和kimi对话,分享之前很有趣的一次对话,现在我们都在做AGI/ASI,可能会有更美好的未来,可以一起去探索宇宙,但是有可能会威胁到人类。
如果你的效果做的非常好,它现在也可以完成很多自动化的任务,甚至后面还会有大幅度的提升, 这个答案很有启发性,它可能不是一个普通工具,而是可以提升人类文明上限的东西。人类认知的延伸,今天我们有很多问题解决不了,很多癌症无法被攻克,有很多能源的问题需要被解决,甚至有很多社会的解决需要更好的设计。我觉得站在kimi讲,它是我们探索未知世界的一个很重要的钥匙。
虽然它有风险,但是它的回答是我仍然会选择继续开发,因为放弃这个开发就意味着放弃人类文明上限。所以,我们不应该害怕技术的风险,而是应该进一步去突破。同时,在这个过程中我们可能把风险控制好,因为所有的技术突破都伴随着风险,不能因为恐惧而停滞不前。
我们希望在接下来的十年、二十年的时间,继续把K4、K5到K100做的更好。
——————————————
雷递由媒体人雷建平创办,若转载请写明来源。